Enhance RL with LLM feedback
Overview
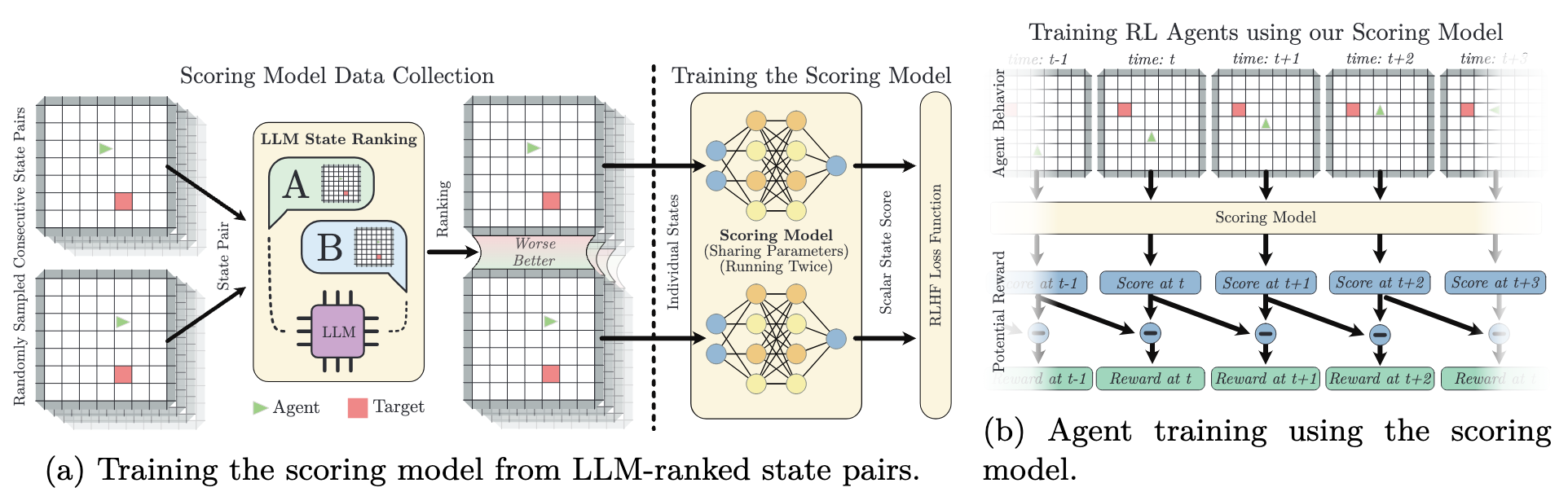
In this work, we study the advantages and limitations of reinforcement learning from large language model feedback and propose a simple yet effective method for soliciting and applying feedback as a potential-based shaping function. As shown in the figure, a state potential function \(\sigma(s)\) is contrastively learnt from LLM feedback state-pair preferences (a). The function further serves as reward generator formulated as \( r(s_t, s_{t+1}) = \sigma(s_{t+1}) - \sigma(s_t) \) (b). We theoretically and empirically show that our approach results in higher policy returns compared to prior works, even with significant ranking errors, and eliminates the need for complex post-processing of the reward function.
Results
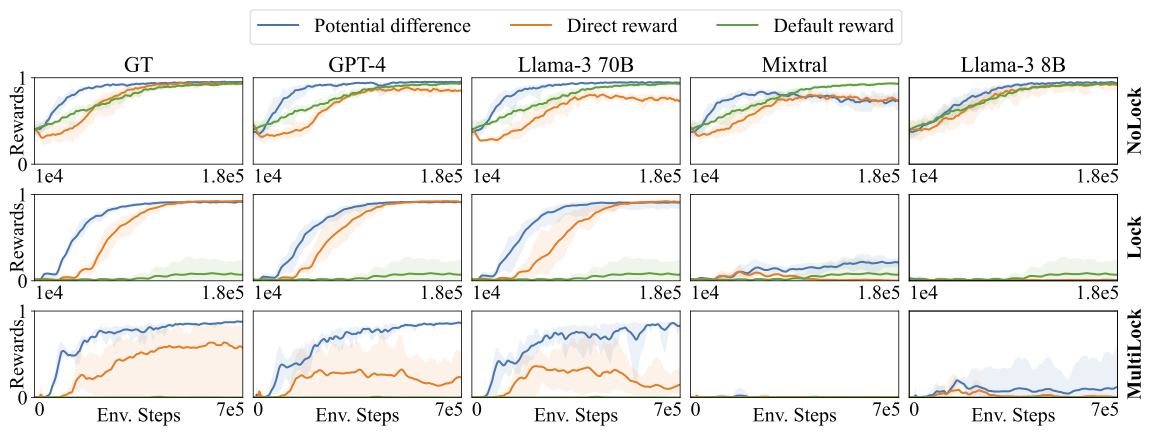
We tested our method in 3 grid-world navigation Variants and 3 Mujoco robot control scenarios. The results for grid-world are shown here.